

Everyone thinks voice AI is a solved problem.
You've seen the demos. An AI agent picks up the phone, greets a customer, books an appointment. It sounds natural. It responds quickly. It switches between languages mid-conversation. An engineering leader watches a two-minute clip and tells me: "We can build this ourselves."
I've watched this play out dozens of times now. Voice AI is showing up everywhere — home services companies booking appointments, grocery delivery platforms reassigning shoppers, food delivery dispatching drivers, marketplaces handling buyer-seller coordination, e-commerce brands processing returns, travel companies rebooking flights. Every industry that runs on phone calls is racing to put an AI agent on the line.
My team built the #1 conversations platform — the API that powers chat for hundreds of millions of users. When we launched Delight, our omnichannel AI platform, we figured voice would be a natural extension.
We were wrong about almost everything.
After 2,000+ production issues resolved, more late-night call recordings than I'd like to admit, and a team that's been genuinely humbled by the gap between demo and deployment — here's what I wish someone had told us before we started.
The constraint triangle
The first thing we learned is that every voice deployment lives inside an impossible triangle: latency, accuracy, and cost. Optimize for one, and the other two move against you.
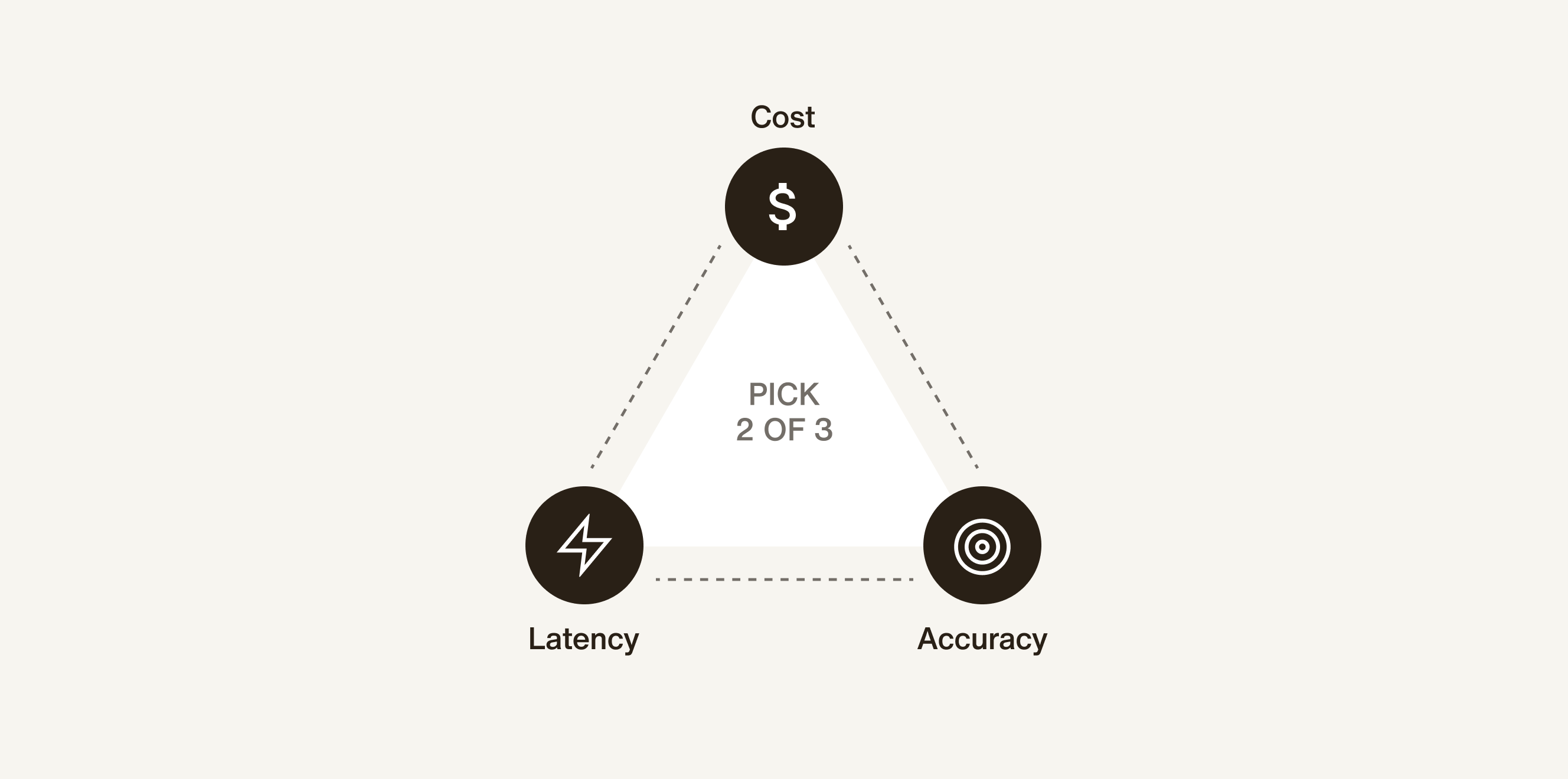
You can push for sub-second response times with real-time speech models — but they cost significantly more and instruction-following gets less predictable. You can maximize transcription accuracy — but the compute bill goes up and latency increases. You can optimize for cost — but your agent sounds slower or makes more mistakes.
There is no globally correct position in this triangle. The right tradeoff depends on the use case, the language, the customer's tolerance for latency, and what they're actually trying to accomplish on the call. A home services appointment booking flow has different requirements than a grocery delivery reassignment workflow. Every deployment is a different position in this triangle — and that position shifts as you add languages, scale volume, or change vendors.
Which brings us to the stack.
The stack underneath
The pipeline shape is simple: STT → LLM → TTS. The complexity is in the vendor matrix underneath — multiple providers at every stage, each with different latency, accuracy, and cost profiles, each behaving differently depending on what language the customer speaks.
Here's a simplified version of what we run in production:
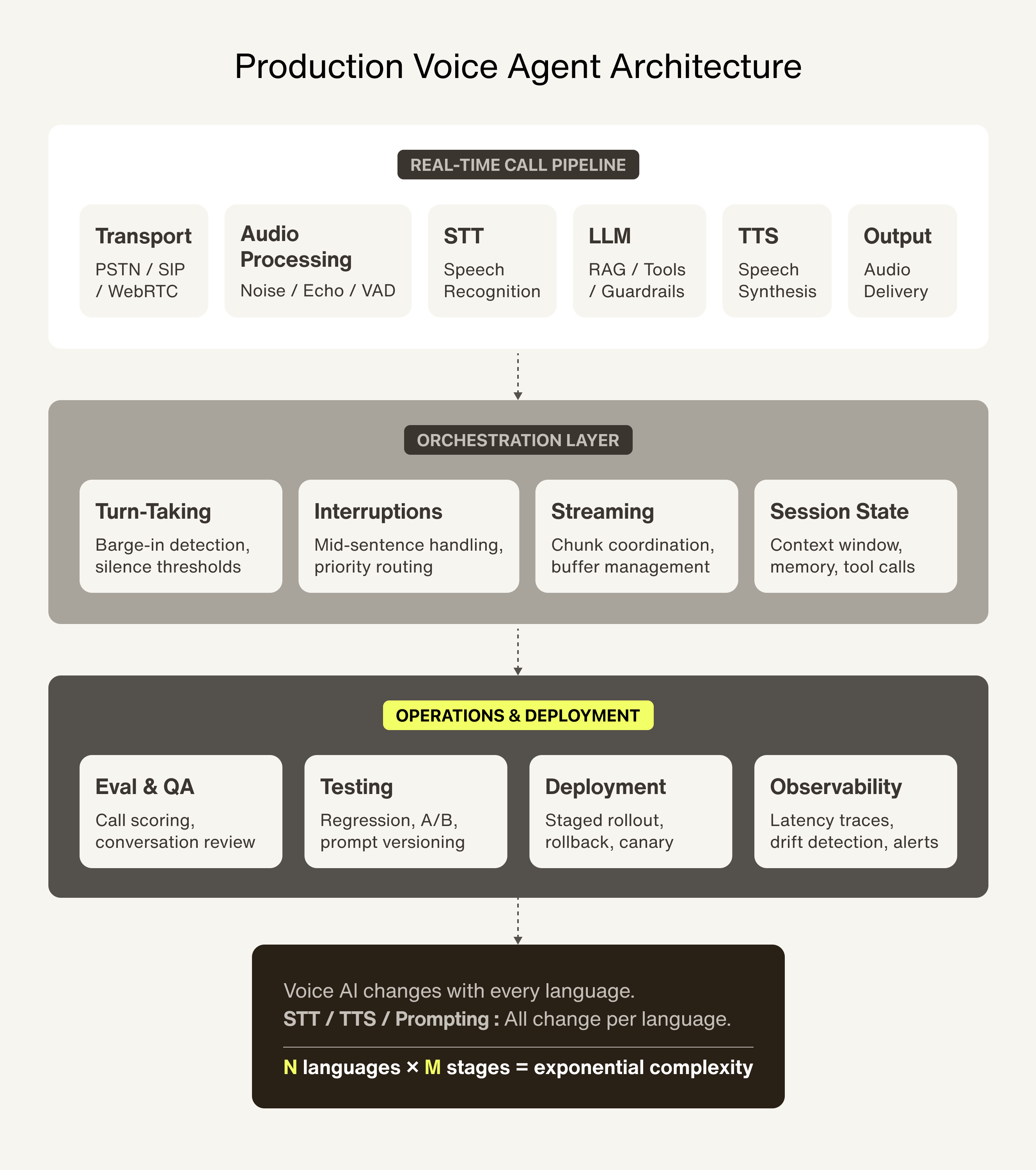
The top row is what people think of as "voice AI." The pipeline. But a production system also needs audio preprocessing — noise suppression, echo cancellation, voice activity detection — before audio even reaches the STT layer. It needs an orchestration layer managing turn-taking, interruption handling, and streaming coordination in real time. And it needs the entire operations infrastructure underneath: evaluation, regression testing, A/B testing, staged rollouts, rollback, observability, post-call analytics.
Then multiply all of it by language. The best STT provider for English isn't the best for Spanish. The best TTS engine for European languages sounds unnatural in Chinese, Japanese, and Korean — wrong rhythm, wrong intonation, wrong emphasis. Prompting strategies change per language. A provider that performs well in benchmarks can still fail on real phone calls with background noise, regional accents, and customers who talk the way people actually talk.
The demo is the top row. The production system is everything else.
Voice breaks differently
Architecture is the knowable part. The hard part of voice AI is the cascade of production problems that you genuinely cannot anticipate until you're handling real calls.
Interruption handling
A customer says "wait, hold on" while the agent is mid-sentence. What should happen? On our first deployment, the agent just kept talking. It sounded terrible. But the fix isn't simple — barge-in sensitivity has to be tuned per use case, and it behaves differently across languages. Too sensitive and the agent stops every time there's background noise. Not sensitive enough and customers feel talked over.
Silence detection
Three seconds of silence. Are they thinking? Looking something up? Or did they hang up? We got this wrong early — our agent would either fill the silence too aggressively or wait too long. The right behavior depends on where you are in the conversation, what question was just asked, and what language you're speaking.
Latency perception
This one surprised us. We had calls where measured latency was technically fine, but customers reported the agent felt "slow" or "robotic." It turned out the perception of speed depends heavily on conversational filler — the "let me check that for you" and "one moment" phrases that humans use instinctively. Without them, even fast responses feel unnatural. With bad timing, they feel worse.
Accent and dialect variance
Our STT pipeline worked well for standard American English. Then we deployed in a market where we needed Spanish support and the speech-to-text provider produced Spanish with an English accent. In another deployment, background noise from the customer's environment degraded transcription accuracy so badly that we had to add a noise cancellation layer we hadn't planned for.

That number isn't a brag. It's an honest accounting of how many things can go wrong in voice that simply don't exist in chat. Each one was a real problem, on a real call, that we had to diagnose and fix. The categories range from latency tuning to accent handling to conversation flow to filler word timing. Most of them aren't documented anywhere because the industry is still figuring this out.
Why we had to unlearn everything we knew about chat
This was our most expensive lesson. We assumed voice agents could share architecture, tooling, and prompting strategies with chat agents. They can't.
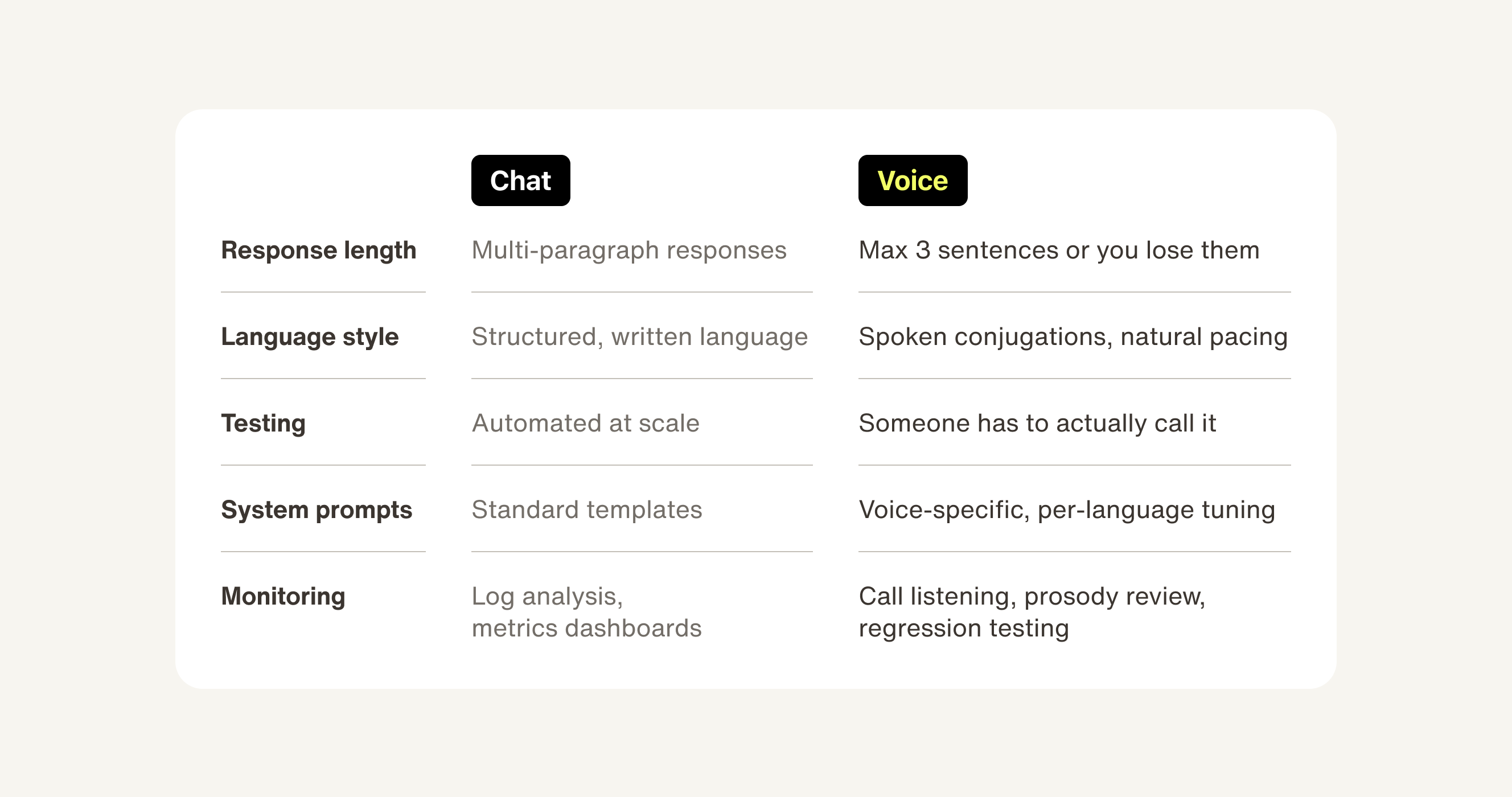
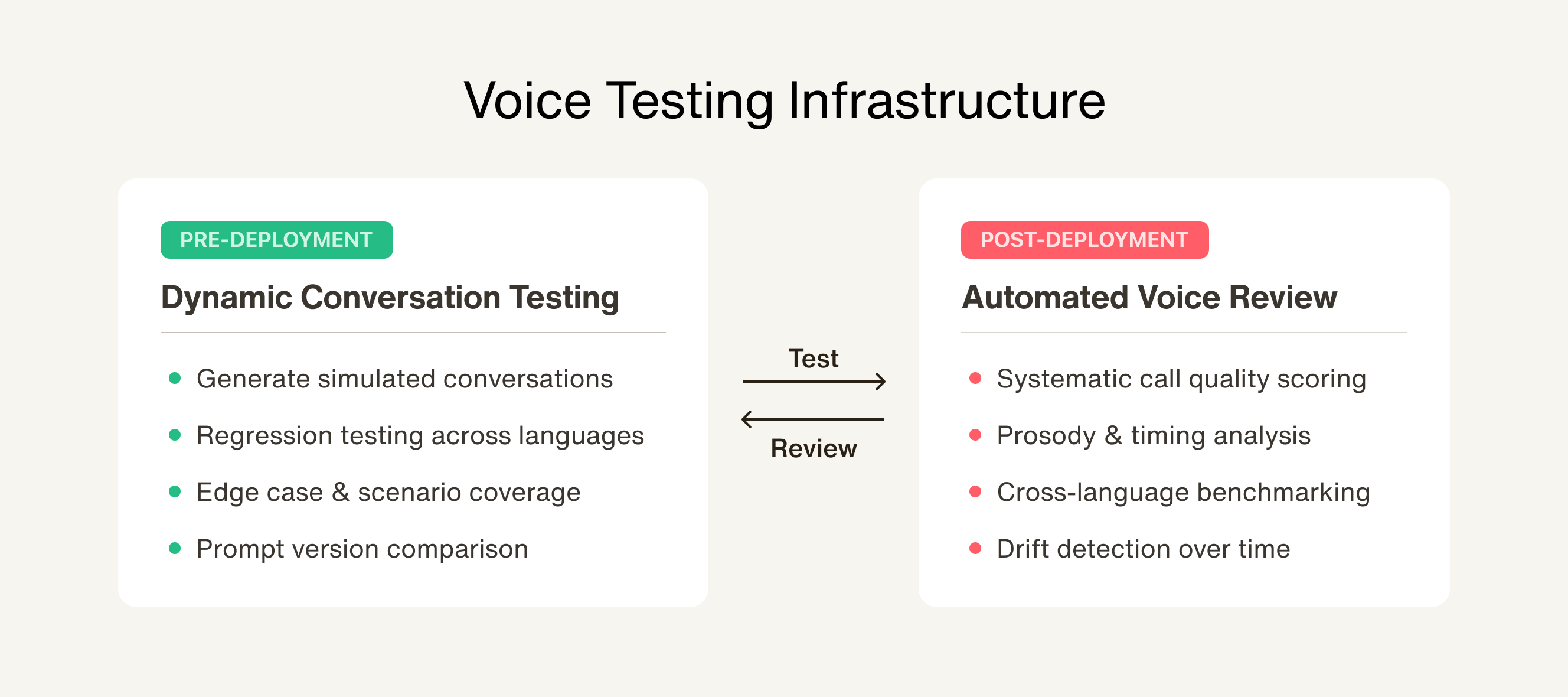
The testing problem alone deserves its own post. With chat, you can write automated test suites that run thousands of conversations in minutes. With voice, someone has to call the phone number and talk to it. There's no good shortcut. No one in the industry has cracked this yet — and it's not for lack of trying.
After enough deployments, you learn that walking the office floor making test calls doesn't survive contact with scale. We've invested heavily in internal tooling to close this gap — including tooling that dynamically generates simulated conversations so we can run regression and scenario testing across languages and edge cases without a human on every call. It doesn't replace human judgment, but it compresses the feedback loop from days to minutes. That's the difference between catching a regression before rollout and finding out from a customer.
The build is the easy part. Maintenance is the job.
I talk to engineering leaders regularly who are confident they can build a voice agent. And they're right — getting a demo working is a few weeks of effort for a strong team. What they underestimate is what comes after.
A production voice agent needs continuous attention. Monthly conversation reviews. Prompt adjustments as customer behavior shifts. Guardrail tuning when edge cases emerge. Regression monitoring when an upstream provider changes their model. When something breaks in voice, it's not a log entry — it's a customer on a phone call having a bad experience in real time.
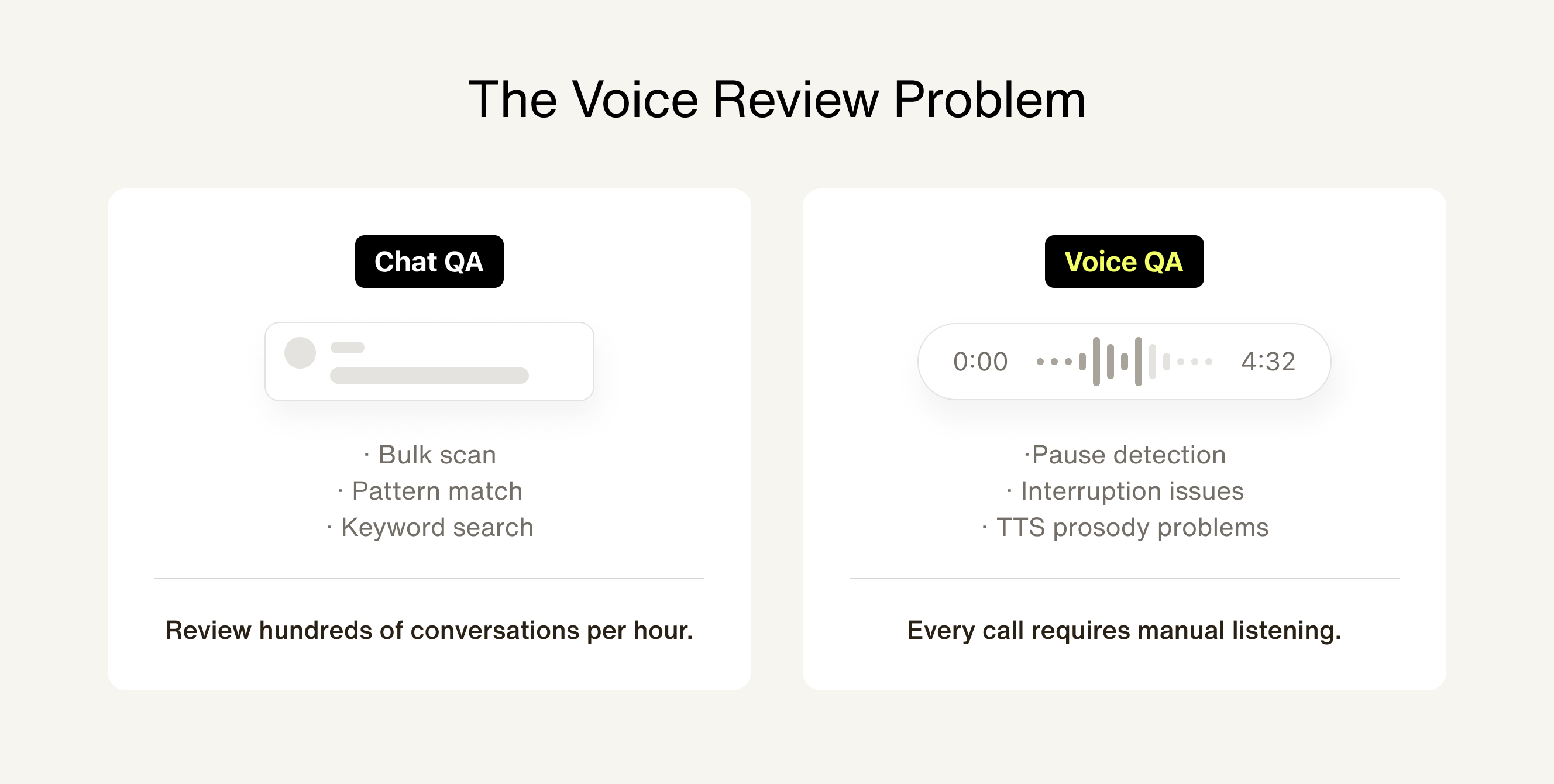
And then there's the review problem. With chat, you can scan conversation logs, run keyword searches, and audit hundreds of interactions in an hour. With voice, you have to listen. You have to hear the pause that was too long, the interruption that felt rude, the TTS prosody that sounded off in Korean but fine in English. Reading a transcript of a voice call tells you what was said — it tells you almost nothing about how it sounded.
We built an internal tool we call SAAV specifically for this: a way to systematically review voice agent quality at scale without requiring someone to sit through every call end-to-end. Without something like it, quality review doesn't scale. And if quality review doesn't scale, quality doesn't hold.
The question isn't "can we build a voice agent?" It's "do we want to staff a dedicated team to maintain it indefinitely?"
Across our deployments, we've seen the full spectrum. Some customers are technically sophisticated and can manage their own configurations with minimal oversight. Others need full-service support. But every single one requires ongoing human judgment to keep quality from degrading. Voice agents don't stay good on their own. They drift. And catching that drift before your customers do requires operational discipline that's separate from the original engineering work.
For most companies I talk to, the honest answer is: they want the agent, not the operations team. And I think that's the right call.
Where we're going: Real-time speech-to-speech
The most exciting development in our work right now is speech-to-speech models — models that process audio directly instead of routing through the STT → LLM → TTS pipeline. We've deployed this approach in production, and the difference is immediately noticeable. Latency drops substantially. The filler word problem largely goes away. Conversations feel more natural.
But it's not a free upgrade. Speech-to-speech models cost significantly more to run. Instruction-following is less predictable than pipelined approaches. And the tradeoff matrix gets more complex, not simpler — you're now choosing between a cheaper, more controllable pipeline and a more natural but more expensive direct model, sometimes varying the choice by language within the same deployment.
Our current approach is a hybrid, and I suspect that will be the industry standard for a while. Real-time models where naturalness and latency matter most. Traditional pipelines where cost efficiency and control take priority. The mix is different for every customer.
The hard part is the moat
Every problem I've described in this post — the latency-accuracy tradeoffs, the orchestration complexity, the per-language configuration surface, the operational discipline required to keep quality from degrading — is a reason most teams will not ship voice AI successfully. Not because they lack talent. Because they underestimate the surface area.
That's the part people miss when they evaluate voice AI. They compare models. They benchmark latency. They ask about STT accuracy. None of that is wrong, but none of it is the hard part. The hard part is the 2,000+ issues you encounter only after you're in production, across languages, at scale — and the tooling, process, and operational muscle you build to handle them.
If you're evaluating voice AI right now, the questions worth asking aren't about which model someone uses. They're about how many production deployments they've shipped, what broke that they didn't anticipate, and what they built to make sure it doesn't break the same way twice. The answers will tell you more than any benchmark.
We've been doing this long enough to know that the playbook doesn't finish. Every new language, every new use case, every new edge case adds to it. That's not a limitation — it's the entire point. The teams that accumulate this operational knowledge fastest are the ones that will own this space. Everything else is a demo.