Humans as AI evaluators

AI agents are capable of managing more conversations than a human agent could. But with that scale comes increased risks like hallucinations, tone drift, or compliance issues. Automated tests help catch some mistakes, but your team still wants to see, judge, and confirm for themselves. With humans as AI evaluators, a part of Trust OS, you have increased human oversight into AI evaluations. Review, grade, and refine AI-handled conversations with the same rigor as QA—ensuring accountability, compliance, and trust at scale.
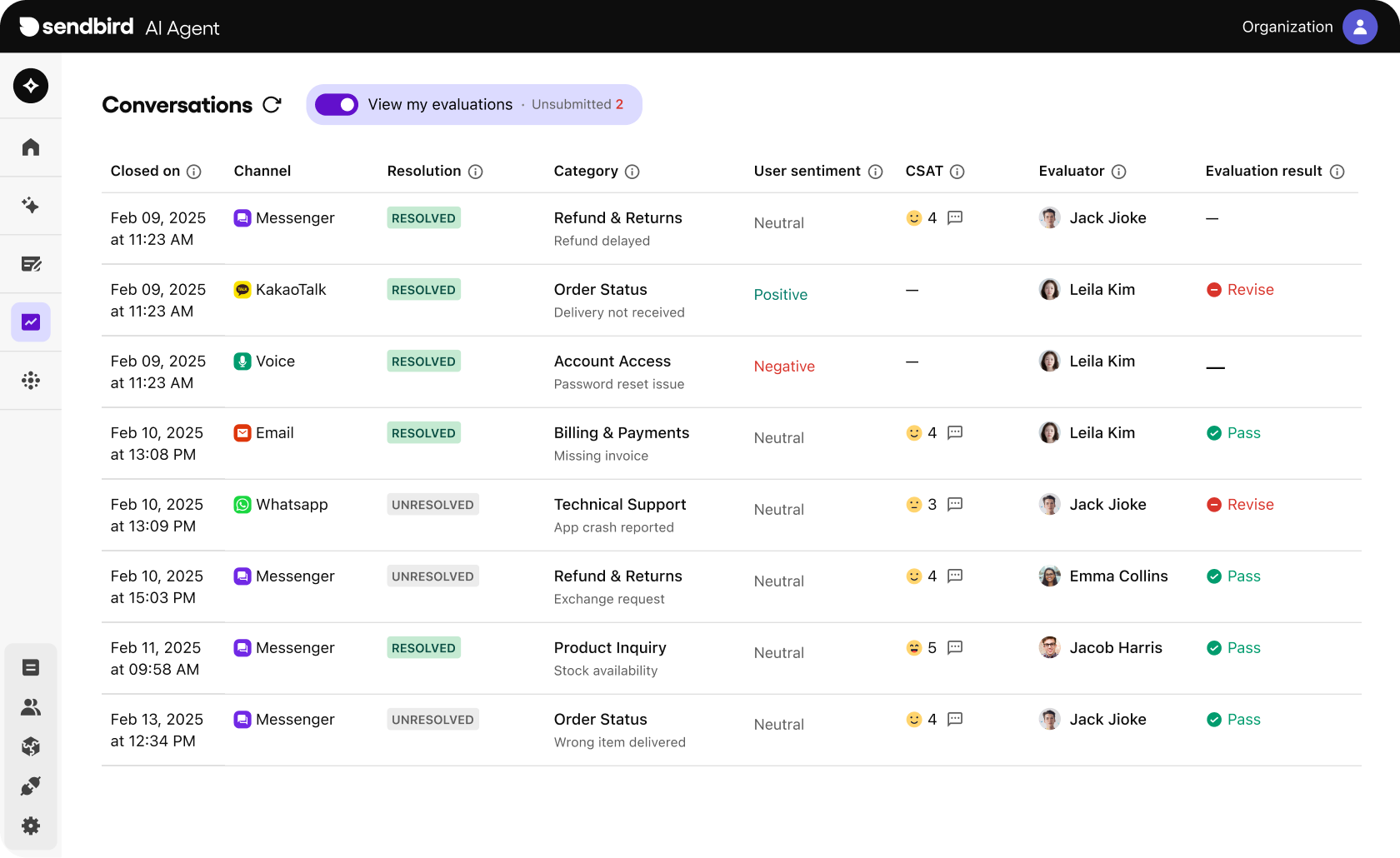
What’s new
- Assign evaluators: Designate reviewers by role, business function, or language.
- Configurable criteria: Evaluate what matters most—tone, clarity, solution effectiveness, and more.
- Evaluator console: View, filter, and manage all conversations under review in one place with interactive views.
- Keyboard shortcuts: Easily move between conversations and submit evaluations all with keyboard shortcuts to streamline high-volume evaluations.
In the agentic-first era, AI can produce many invalid responses—judged for tone, reasoning, and outcome. With humans as AI evaluators, your agent understands where mistakes were made and learns from them. QA should be a system design principle with actionable next steps, not a spot-check process.