

When you change an Actionbook, update your agent’s knowledge base, or swap in a new model, you expect things to get better. But with AI agents, the connection between a change and its outcome is rarely obvious. A refund flow that reads more naturally might actually confuse users in ways that drive up recontact rates. A shorter greeting might improve response times while quietly lowering satisfaction. By the time the damage shows up in your metrics, you may have already heard about it from customers.
Delight.ai’s Trust OS 2.0 adds two tools to close that gap: Gradual Rollout and A/B Testing. Both run two versions of your agent side by side against real traffic, but they answer different questions.
Gradual Rollout asks whether a change is safe to ship
The core problem gradual rollout solves is exposure. Before it existed, every change you promoted to production was immediately live for every customer. Even with instant rollback, you’d already affected thousands of conversations by the time a problem surfaced.
Gradual Rollout lets you start smaller. When you promote a change from staging, it becomes a candidate running in the Idle slot alongside your Live slot. You set the traffic split (1% to the candidate, 99% to live), let real conversations accumulate, and watch the metrics. Resolution rate, CSAT, and containment rate are all tracked separately for each slot. If the numbers look good, you scale up. If something’s wrong, you cut the Idle slot’s traffic to zero instantly. The Live slot never changes; you’re just dialing the candidate in or out.
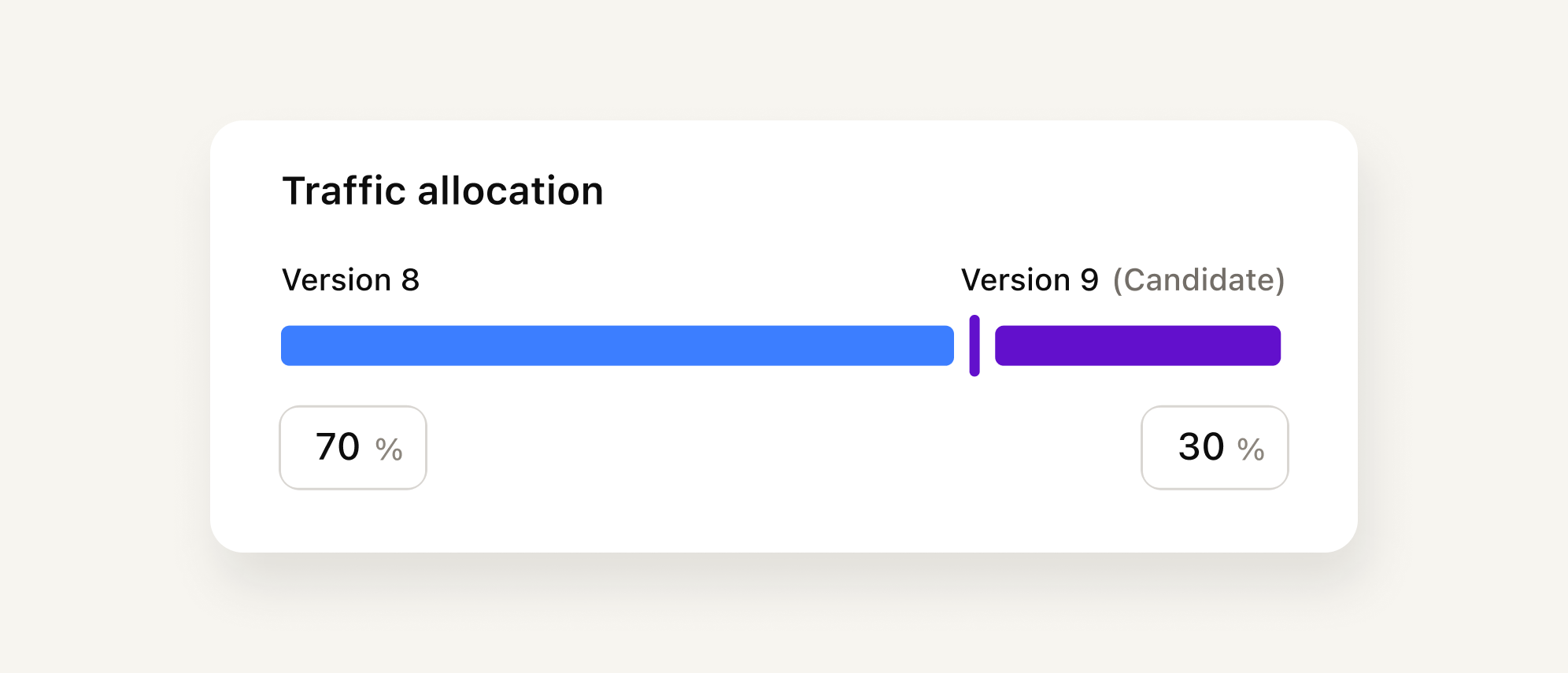
With gradual rollout, a bad deploy is still a bad deploy. It just affects 1% of your traffic, not 100%. And you see it before you’ve fully committed.
When you’re satisfied with the candidate’s performance, you promote with a single action. Traffic flips to 100% on the new version and the previous version is kept as a backup. Every version in your history is preserved as a candidate, so you can re-run any previous configuration at any time.
A/B Testing asks whether a change actually improved things
Gradual rollout answers the safety question well. What it doesn’t answer is whether the change actually made things better. “No obvious regressions” and “statistically meaningful improvement” are two different things. If you’re trying to optimize rather than just ship safely, you need the latter.
That’s what A/B Testing adds. The mechanics are familiar: two versions of your agent run in parallel, traffic is split between them, and results accumulate from real conversations. The difference is how you frame and measure the outcome.
Before the test starts, you articulate a hypothesis. Something like: if we simplify the refund Actionbook from five steps to three, resolution rate will improve. You pick a target metric. The system calculates how many conversations you’ll need to reach a statistically meaningful conclusion and estimates how long that will take at your current traffic volume.
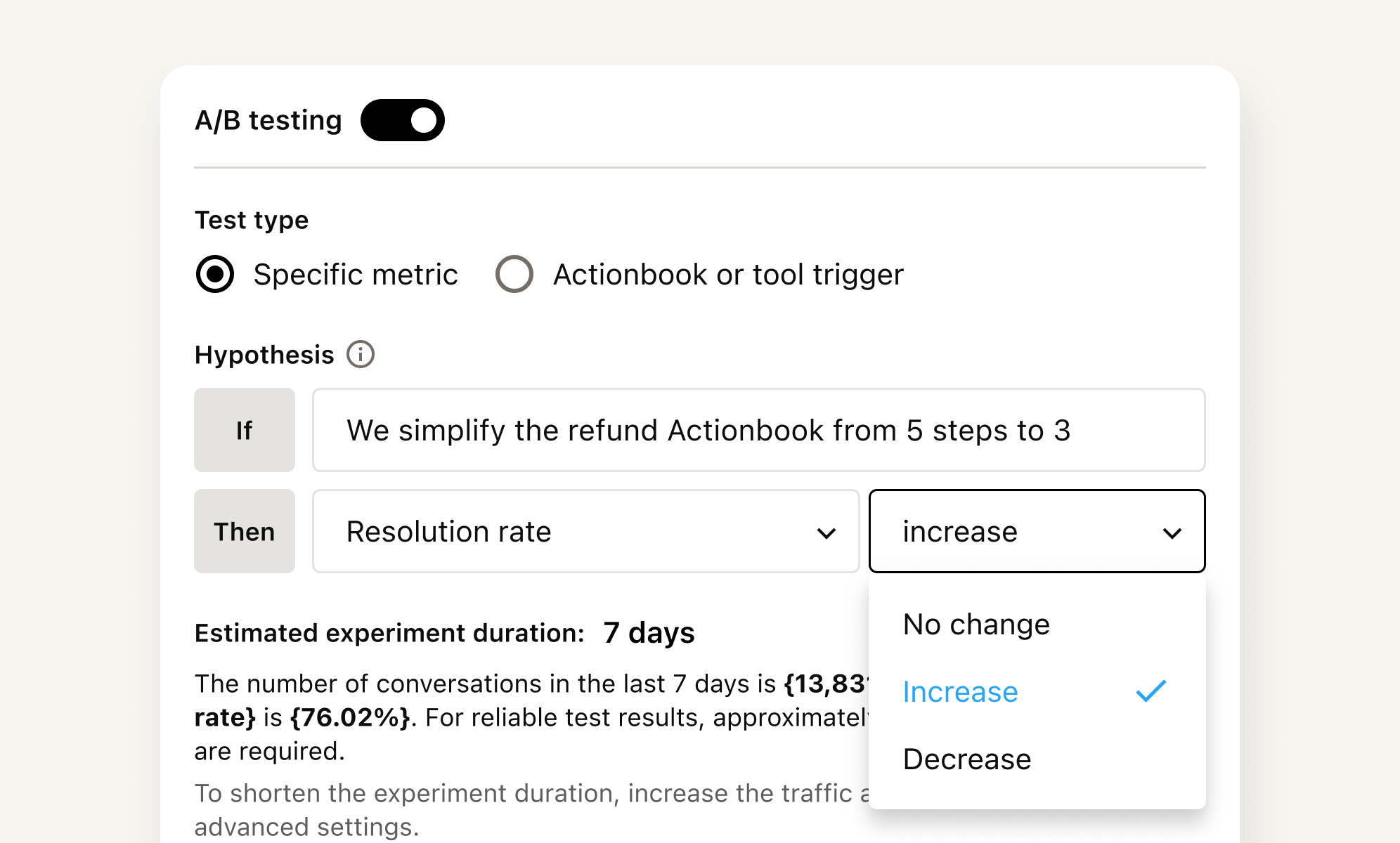
While the test runs, traffic is locked, since changing the split mid-experiment would corrupt the results. When you end the test, results are evaluated against your hypothesis. The key output is a result reliability score, expressed as a percentage, that tells you whether the difference you’re seeing is real or noise.
- 95% or higher (High): The result is reliable enough to act on.
- 80–95% (Medium): Trending in the right direction, but not yet confirmed.
- Below 80% (Low): Not enough data yet to draw a conclusion.
Every completed test generates an AI analysis report covering what changed, what improved, which secondary metrics to watch, and what to try next. Secondary metrics that moved in the wrong direction are flagged with their own reliability score, so you can tell whether a potential tradeoff is a real concern or just noise.
Use gradual rollout to ship safely, A/B testing to prove it worked
Gradual rollout is for shipping safely. A/B testing is for proving something worked.
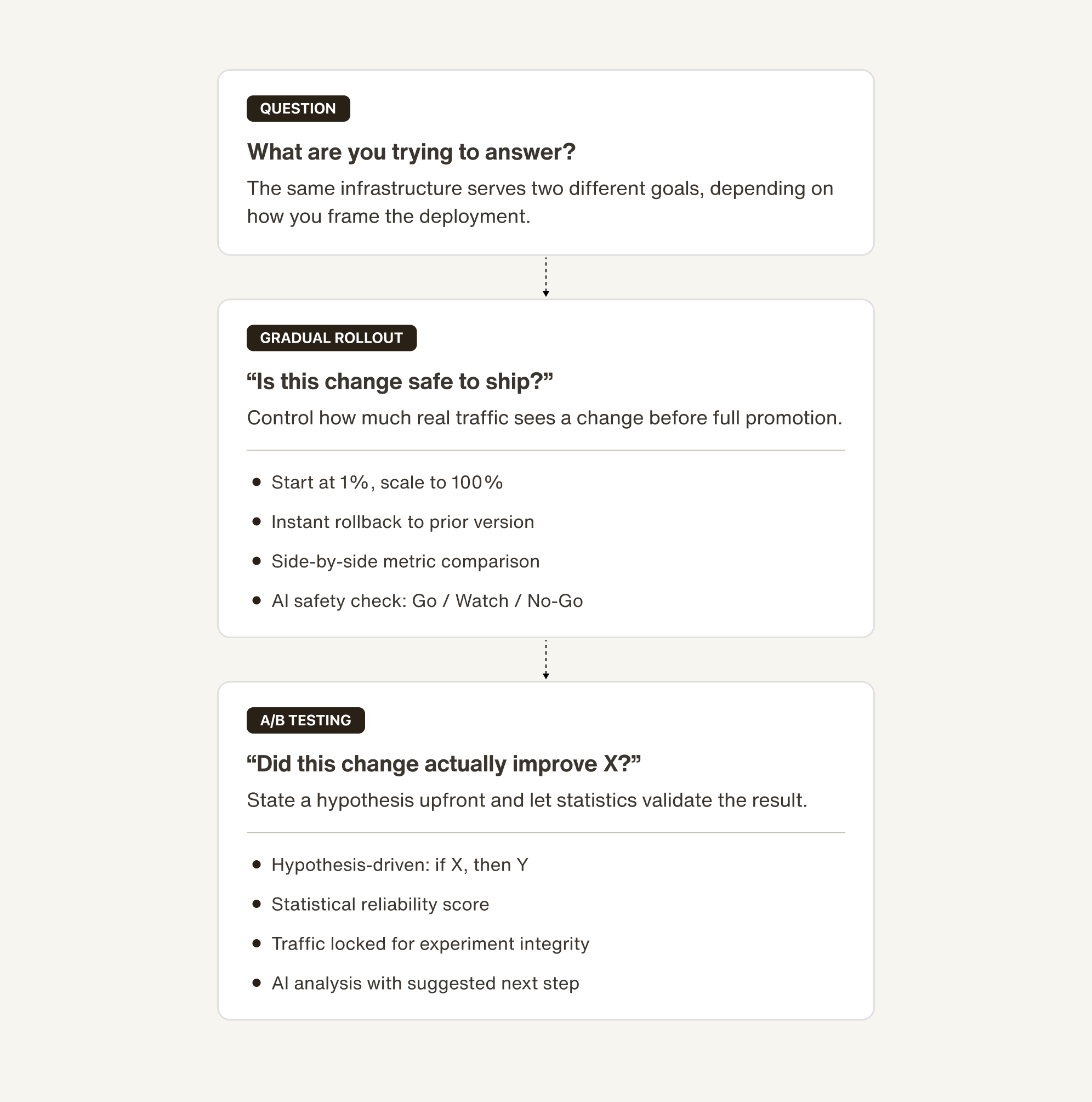
If your primary concern is stability and you want to limit blast radius on a meaningful change, gradual rollout is the right tool. No hypothesis required, no traffic lock. You just need to know it’s safe before you fully commit.
If you’re optimizing and want to know whether a specific change to an Actionbook, knowledge base, or model actually moved a metric you care about, A/B testing gives you the statistical rigor to distinguish signal from noise. It also measures tool call rates, so if your change is supposed to reduce unnecessary coupon issuances or cut escalations, you can verify that directly.
Both features are part of Trust OS, delight.ai’s operational layer for running AI agents at production scale. Trust OS brings together the deployment controls, governance, and observability that enterprise teams need to move quickly without losing oversight of what their agents are doing.



