

Writing test cases for an AI agent has always required a leap of faith. You describe what a conversation should look like, guess what the agent should do, and hope the synthetic inputs cover the edge cases that matter. By the time real failures show up in your test results, the test you wrote probably wasn’t close enough to the real conversation to tell you why.
Test has been rebuilt. The new Test Upgrade closes the gap between the test suite you maintain and the agent behavior you actually care about.
Start from real conversations, not blank test cases
The most common bottleneck in AI agent testing is the test case itself. Synthetic inputs are slow to write and inevitably drift from what customers actually do. A simulated returns conversation and a real one are different in ways that matter — and when a test written against the simulation passes, that doesn’t mean much.
Test Upgrade fixes the mismatch. Test cases can now be built directly from real customer conversations, so the inputs your test suite runs against reflect how people actually interact with your agent. You can bring in individual conversations or build out coverage in bulk — either way, you’re testing against reality rather than a guess about it.
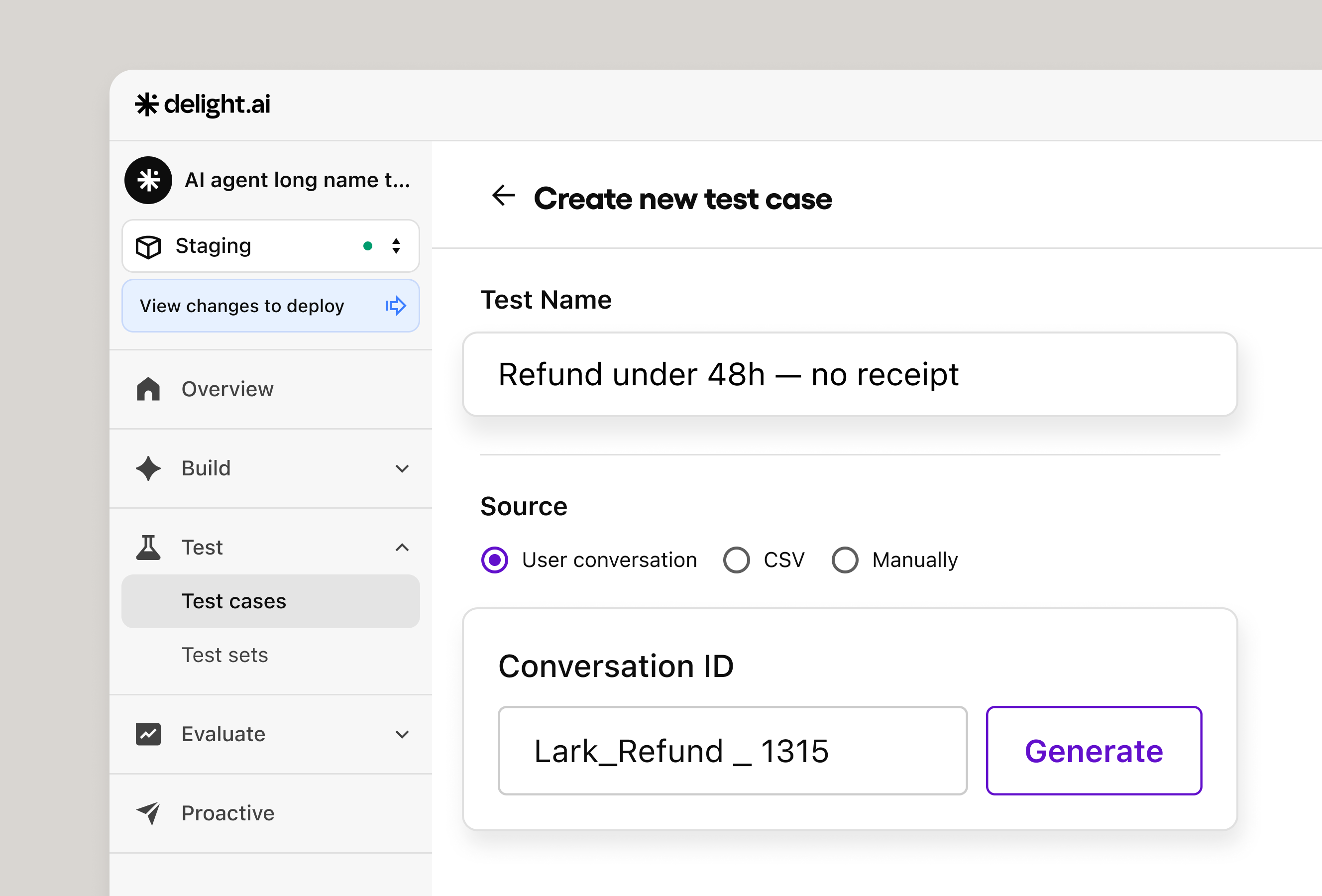
Your best test cases are already in your conversation history. Test Upgrade lets you use them.
Organize once, run anywhere
As test sets grow, the problem shifts from creation to management and reuse. Test Upgrade adds labels — tags you apply to test cases for grouping and filtering. Tag everything in the returns flow and run it with one click. Isolate edge cases for a targeted review. Build the structure that matches how your team thinks about coverage, and use bulk selection to act on groups at once.
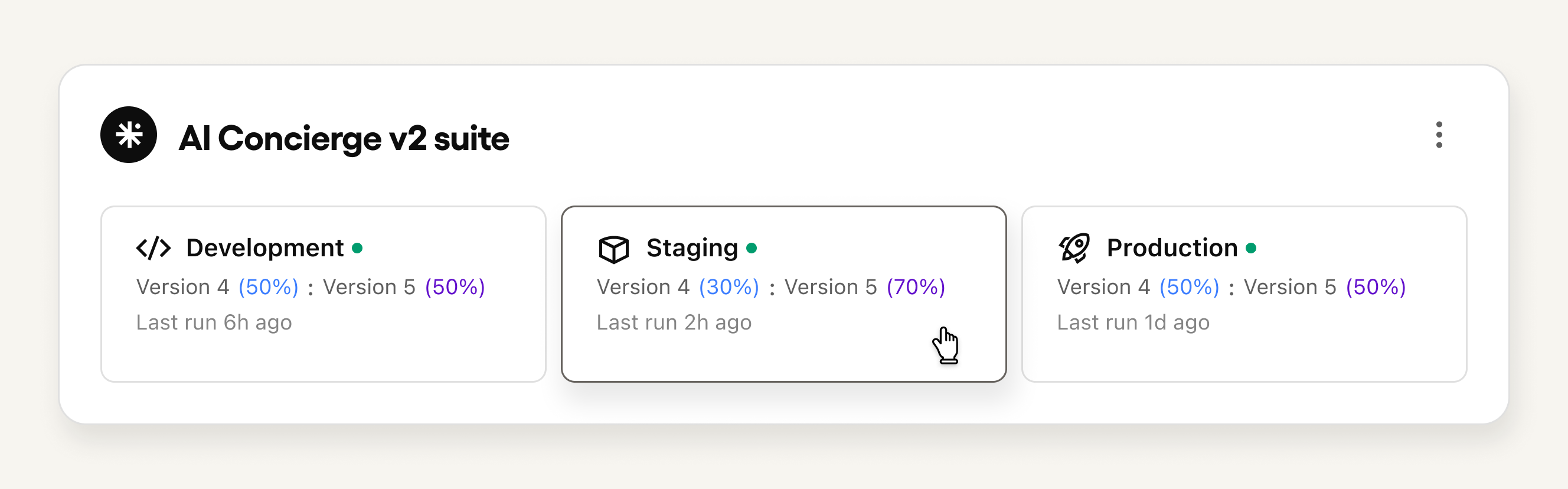
The bigger change is portability. Before, you’d build a test set for one environment and rebuild it — or just skip testing — when you moved to the next. Now a single test set travels with your agent from development through staging to production. The same coverage that caught a problem before you shipped is the same coverage that confirms everything held once you did.
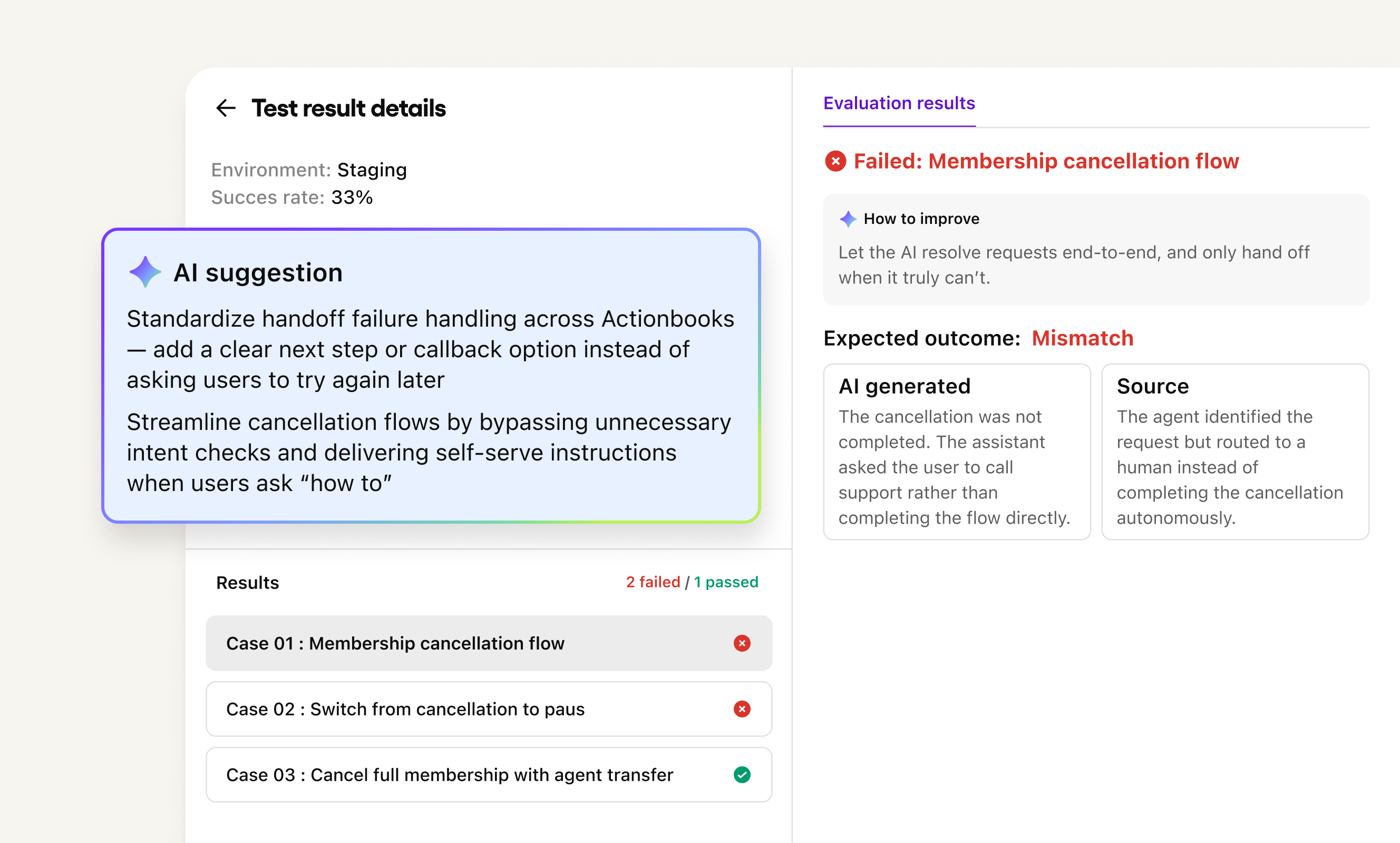
Pass/fail results you can act on
Knowing a test failed is the easy part. Knowing what to fix is harder. Test Upgrade improves failure analysis so that when a case fails, you get enough context to act on it — what the agent did, where it went wrong, and where to focus next — rather than a result that sends you back to square one.
Test Upgrade is part of Trust OS, delight.ai’s operational layer for running AI agents at production scale. Alongside staging environments, gradual rollout, and A/B testing, it’s part of the same system designed to give teams the confidence to ship changes without losing visibility into what their agent is doing.



