

Your AI passes 50,000 test conversations at 100% accuracy. Every scenario handled. Every edge case covered. Every metric green.
Then a real customer says something your tests never imagined — and your AI falls flat.
This is the local maxima problem, and it affects every AI team that's optimized their way to a plateau. Your AI isn't getting smarter. It's getting more efficient at being the same.
Today, we're introducing Zero-Touch Improvement — an AI improvement system that graduates from human-guided learning to fully autonomous optimization, no human touch required. Part of Trust OS 2.0, ZTI is how your AI gets better while you sleep.
Your AI is optimizing. It's not improving.
Every AI team hits this wall. You've fine-tuned your model. You've iterated through hundreds of prompt variations. Your AI is excellent — within the boundaries you've defined.
But those boundaries are the problem. A fully autonomous AI optimizes within its training distribution — it finds edge cases in your test suite and patches them, but it's not learning anything new. Your AI handles 95% of cases flawlessly. The other 5% — the novel scenarios, the situations that require judgment — those are the ones your customers remember.
Optimization makes your AI faster at what it already knows. Improvement teaches it what it doesn't.
Why "just add more autonomy" doesn't work
The instinct is obvious: if AI is good, more autonomous AI must be better. Remove the human. Speed things up. Let the machine run.
But full autonomy without a feedback mechanism is a ceiling, not a destination.
The test suite trap. Your AI optimizes against your tests. But your tests are a model of reality, not reality itself. An AI that scores 100% on 50,000 test conversations hasn't mastered customer service — it's mastered your test suite.
The drift problem. Customer needs change. Products evolve. Policies update. Your AI's behavior was optimized for last quarter's reality. Without a mechanism to learn from what's happening now, it slowly drifts out of alignment.
The unknown unknowns. The hardest conversations aren't the ones you've prepared for. They're the ones you couldn't have predicted — and they can't be solved with a bigger test suite.
The human is what teaches AI what the tests can't.
The autonomy ladder: A graduated path to zero-touch
Zero-Touch Improvement isn't a switch you flip. It's a path you walk. Four levels, each building trust and capability on the one before it.

Level 0: Manual. The status quo. Your team manages every prompt change, every rule update, every test manually. It works, but it doesn't scale.
Level 1: AI proposes, human approves. Your AI starts proposing improvements — new test cases, prompt adjustments, workflow optimizations. Nothing ships without human review. You're building trust.
Level 2: Human steers the loop. Once your AI-human match rate exceeds 97%, you unlock autonomous improvement within approved boundaries. The AI handles research, testing, and deployment. The human sets direction and intervenes on judgment calls.
Think of it like managing a great team member. You don't review every email they send. You set the strategy, check in on the important decisions, and trust them with the rest.
Level 3: Zero touch. The human steps out of the loop entirely. The AI runs the full improvement cycle — research, hypothesis, testing, deployment — continuously and autonomously. Not because the human doesn't matter. Because the human already did the hard work: they steered the system to the point where it can steer itself.
How the improvement loop works
At Level 2, here's what the improvement pipeline looks like:
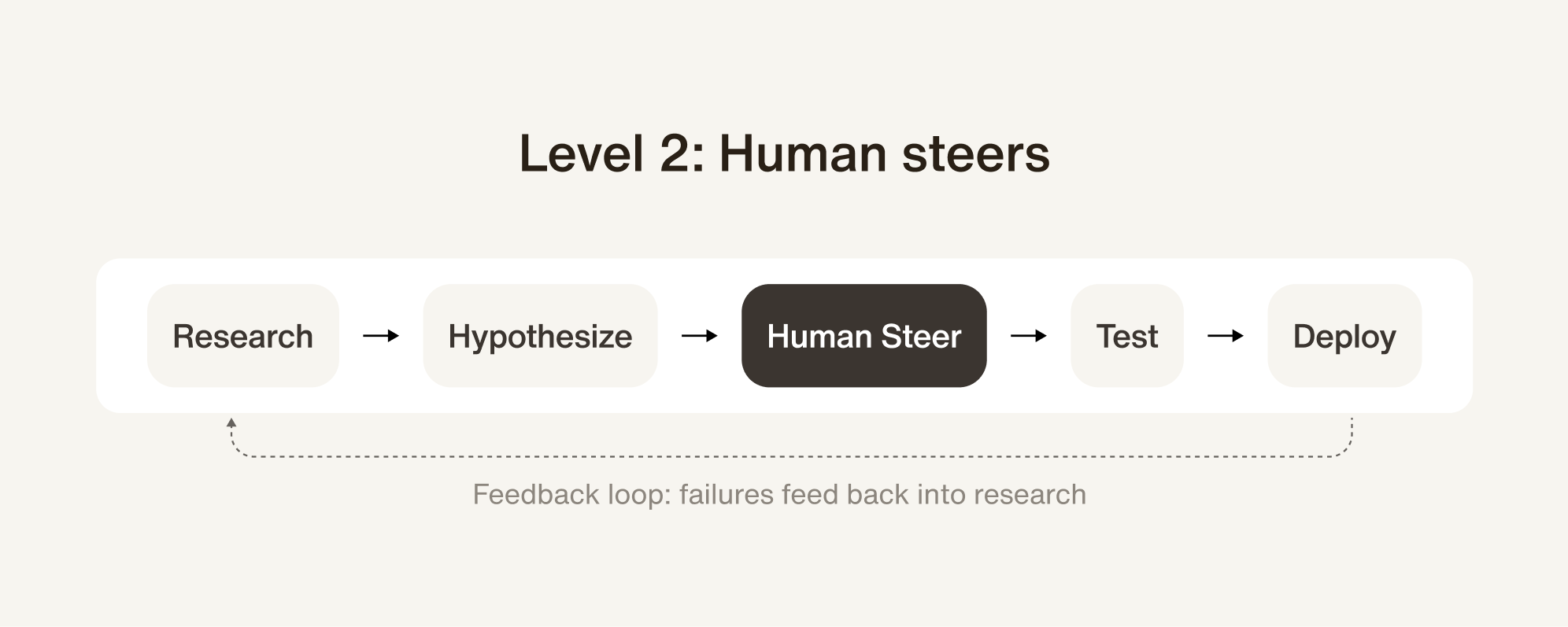
Each step is a concrete product experience, not an abstraction:
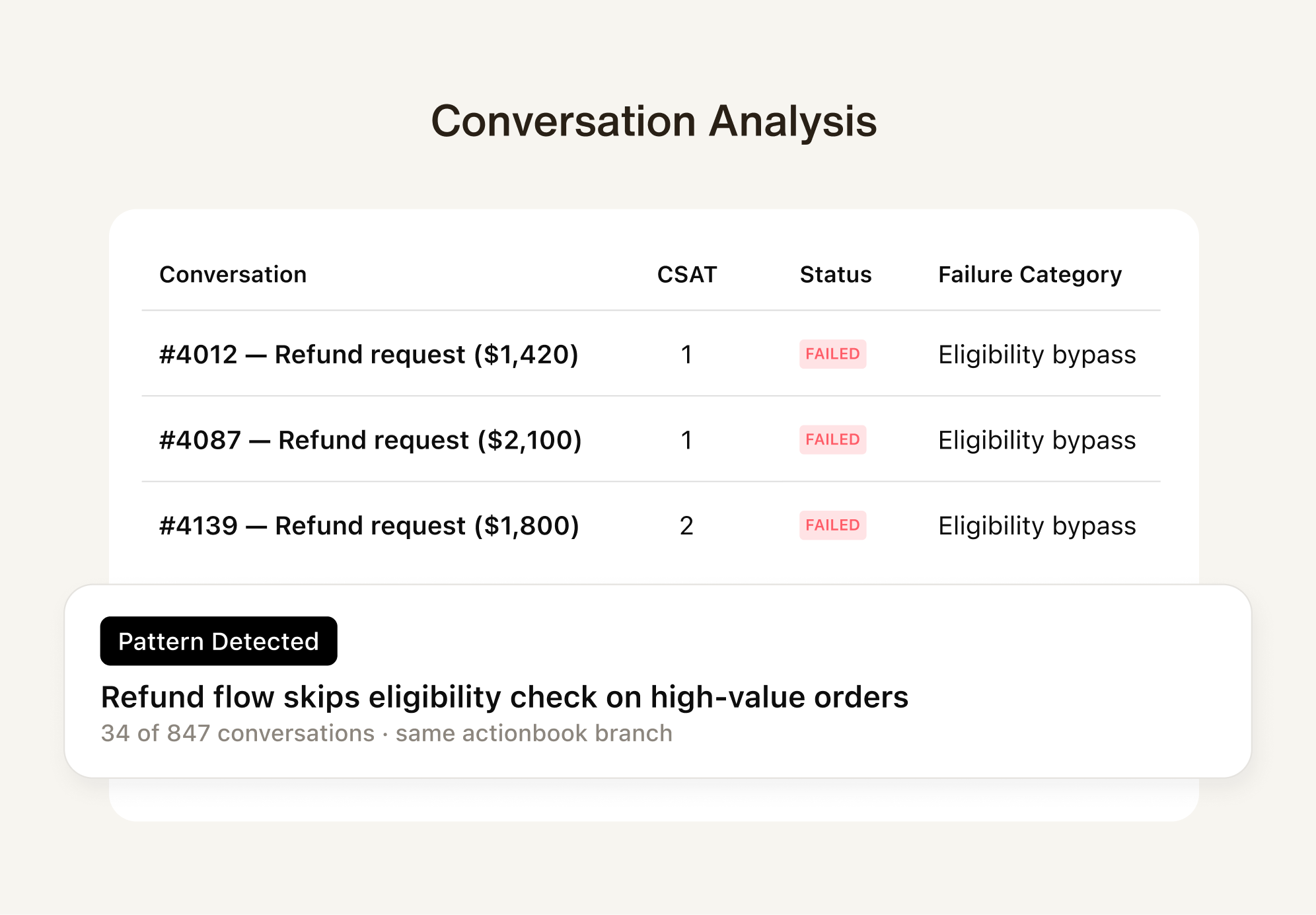
Research — ZTI scans real conversations — not test cases. It finds the 34 out of 847 that failed, clusters them by root cause, and surfaces the pattern: a specific actionbook branch is skipping an eligibility check on high-value refunds.
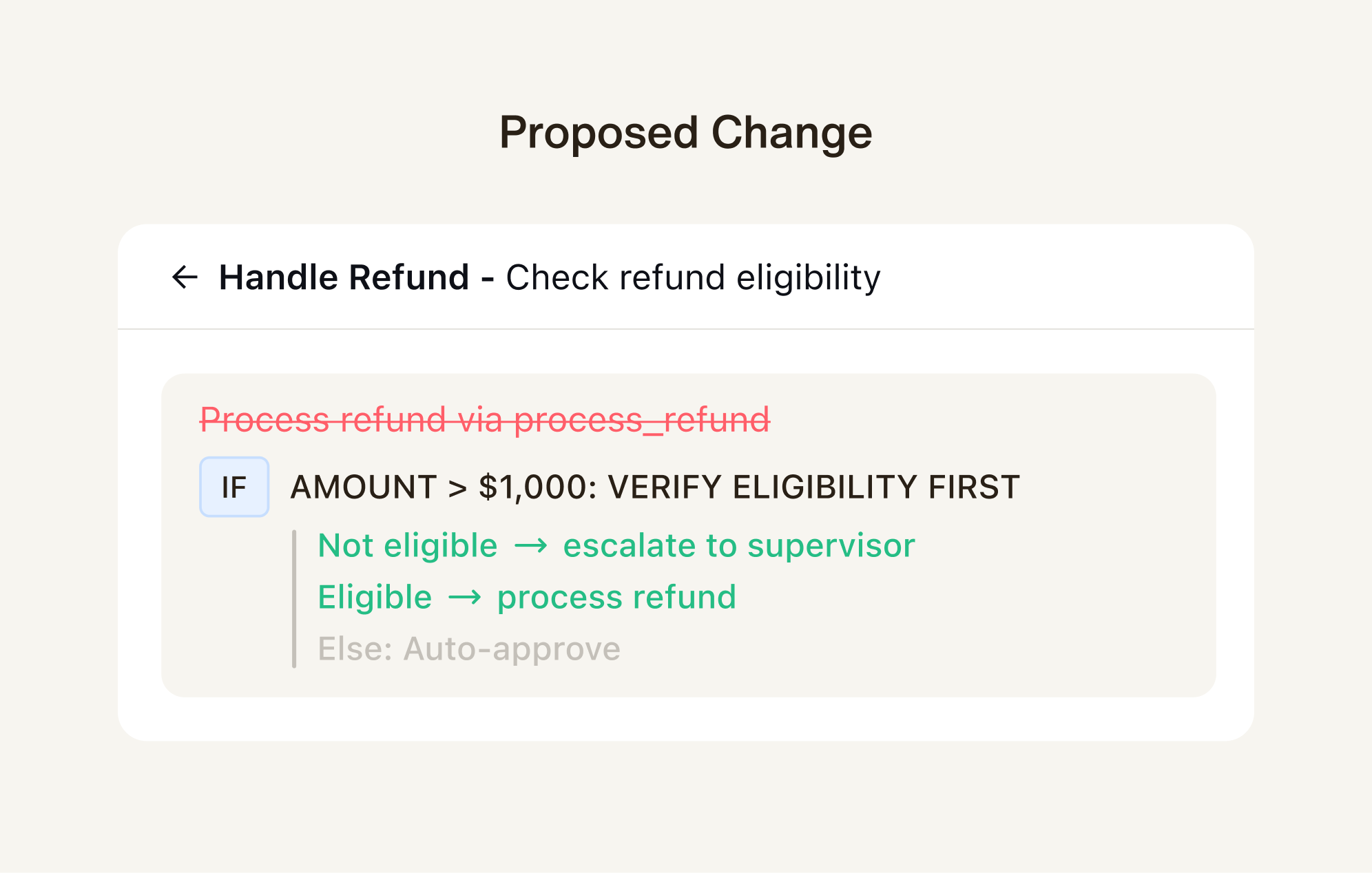
Hypothesize — ZTI doesn't say "update the prompt." It proposes a precise change — with an actionbook diff showing exactly what's being added, removed, and modified. You see the proposed fix in context, not in the abstract.
Human steer — Your team reviews the proposal. They might approve it, scope it ("don't touch the escalation logic in Step 3"), or reject it. Every decision teaches the system not just what to improve, but how your team thinks about improvement.

Test & deploy — The fix is tested against those same 34 real conversations. Iteration 1: 85%. ZTI refines and retests. Iteration 2: 94%. Refine again. Iteration 3: 100%. The change ships to production.
At Level 3, the human node disappears.
This is the dramatic beat. You don't read "zero touch" — you see it. The human node collapses out of the pipeline. The gap closes. Four stages remain.

The pipeline runs faster. The improvements compound. No human bottleneck. No sprint cycles. Just continuous, autonomous evolution.
It never stops improving.
What changes for your team

The AI handles the volume. Your team raises the ceiling.
Built on Trust OS
Zero-Touch Improvement runs on the same Trust OS infrastructure that governs everything at delight.ai:
- Openbook — Every improvement is fully traceable. See what changed, why it changed, and what the measured impact was. No black boxes.
- Actionbook Editor — The rules your AI follows are editable documents, not buried code. When ZTI proposes a change, you see exactly what's being modified — in plain language.
- Staging Environment — Every improvement is tested before it touches production. Real conversation data, controlled conditions, measured outcomes.
- Approval Gates — Even at Level 3, you set the boundaries. Financial thresholds, compliance requirements, sensitive topics — you define what the AI can and can't change autonomously.
Why we didn't just ship full autonomy
We could have shipped a fully autonomous improvement system on day one. The models are capable.
We didn't. Because AI optimizes within the box. Human steering is how you raise the bar.
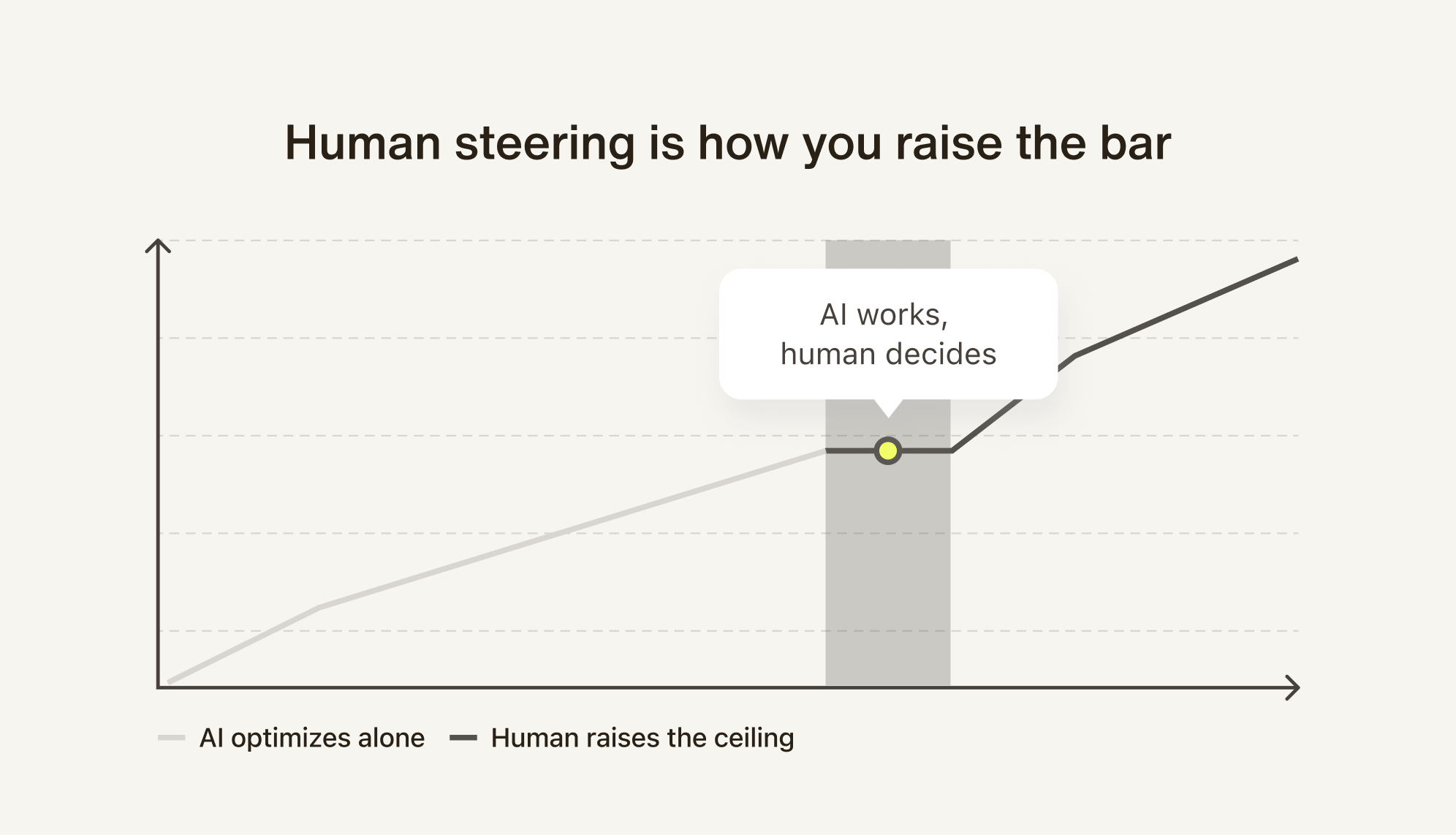
Every frontier AI model improves this way. Human feedback is the signal that breaks through local maxima. The same applies to your AI agent — the human catches what the metrics can't: wrong tone, edge cases, judgment calls that need context.
An AI that's never been steered by humans doesn't know what good looks like. It optimizes for metrics — resolution rate, handling time, CSAT scores — but metrics are proxies, not goals. A human understands that sometimes the right answer takes longer. That sometimes the "optimal" response isn't the one that tests best — it's the one that builds the relationship.
Human steering at Level 2 isn't a limitation. It's the training phase. Every decision your team makes teaches the AI not just what to do, but why. And that "why" is what makes Level 3 possible.
See it. Steer it. Let it learn.
Zero-Touch Improvement is available now as part of Trust OS 2.0.
Start at Level 1. Let your team build confidence. Graduate to Level 2 when you're ready. And when the data shows your AI has earned it — let it run.
Your AI gets better while you sleep.



